14-text-case-study
Load the Data
en_coursera_reviews <- read_csv("https://stat220-s25.github.io/data/en_coursera_sample.csv")
glimpse(en_coursera_reviews)Rows: 26,882
Columns: 5
$ CourseId <chr> "nurture-market-strategies", "nand2tetris2", "schedule-proje…
$ Review <chr> "It would be better if the instructors cared to respond to q…
$ Label <dbl> 1, 5, 5, 5, 5, 5, 5, 3, 5, 1, 5, 5, 5, 4, 5, 5, 5, 5, 5, 5, …
$ cld2 <chr> "en", "en", "en", "en", "en", "en", "en", "en", "en", "en", …
$ review_id <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 1…Tokenize
library(tidytext)
en_coursera_reviews |>
unnest_tokens(output = word, input = Review) |>
select(CourseId, word)# A tibble: 666,493 × 2
CourseId word
<chr> <chr>
1 nurture-market-strategies it
2 nurture-market-strategies would
3 nurture-market-strategies be
4 nurture-market-strategies better
5 nurture-market-strategies if
6 nurture-market-strategies the
7 nurture-market-strategies instructors
8 nurture-market-strategies cared
9 nurture-market-strategies to
10 nurture-market-strategies respond
# ℹ 666,483 more rowsCount the tokens
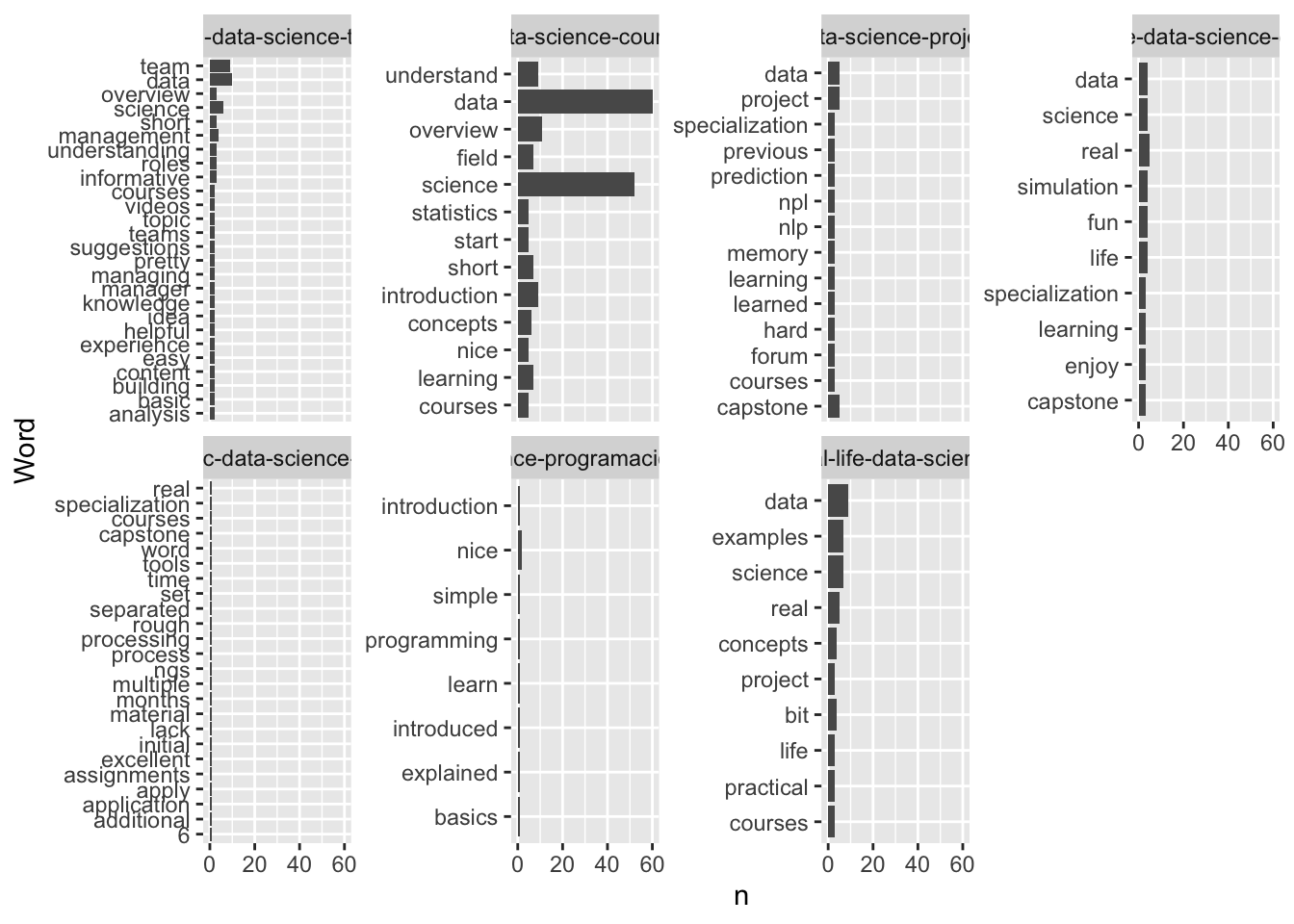
en_coursera_reviews |>
unnest_tokens(output = word, input = Review) |>
anti_join(get_stopwords(source = "stopwords-iso"), by = "word") |>
filter(str_detect(CourseId, "data-science")) |>
group_by(CourseId) %>%
count(word) %>%
slice_max(n, n = 10) %>%
ggplot(aes(x = n, y = fct_reorder(word, n))) +
geom_col() +
facet_wrap(~CourseId, scales = "free_y", nrow = 2) +
labs(
y = "Word"
)
Create “clean” reviews
coursera_reviews <- en_coursera_reviews |>
unnest_tokens(word, Review) |>
anti_join(get_stopwords(source = "stopwords-iso"), by = "word") |>
group_by(CourseId, review_id) |>
summarize(review_clean = paste(word, collapse = " "))Your turn
Explore the en_coursera_reviews dataset with the folks around you. Can you replicate my analyses, and try a few of your own? Here are some ideas:
- Explore another subject (besides
data-science) -
Labelcontains the numeric rating for the course. How does the review text differ between highly rated and low-rated courses? -
stopwords::stopwords_getsources()gives the available stopword dictionaries. How do these differ, and how do they change your results?