Working with
Strings
Day 12
Carleton College
Stat 220 - Spring 2025
Today
- Lab Quiz 2 Info
- Local versions of R/RStudio/GitHub
- Intro to strings
Lab Quiz 2 Info
Local Versions of R/RStudio/GitHub
https://stat220-w25.github.io/computing/rstudio-stat220.html https://stat220-w25.github.io/computing/git-stat220.html
string
any finite sequence of characters (i.e., letters, numerals, symbols and punctuation marks).
Strings in R
Anything surrounded by quotes(") or single quotes(').
str_view
str_view is a handy function that prints the underlying representation of a string and can also be used to check pattern matching (which we’ll see in a bit!)
The “escape” backslash is used to escape the special use of certain characters
Error: '\S' is an unrecognized escape in character string (<input>:1:16)String length
str_length() determines the length of a string.
Combine strings
str_c() allows us to easily create strings from variables/vectors.
[1] "STAT 220 meets from 9:50 a.m. to 11:00 a.m. MWF in CMC 102"Concatenate Strings
str_c() works with vectors
[1] "a" "b" "c" "d" "e" "f" "g" "h" "i" "j" "k" "l" "m" "n" "o" "p" "q" "r" "s"
[20] "t" "u" "v" "w" "x" "y" "z"Case conversion
str_to_lower() and str_to_upper() can help “fix” the case
Babynames
# A tibble: 1,924,665 × 5
year sex name n prop
<dbl> <chr> <chr> <int> <dbl>
1 1880 F Mary 7065 0.0724
2 1880 F Anna 2604 0.0267
3 1880 F Emma 2003 0.0205
4 1880 F Elizabeth 1939 0.0199
5 1880 F Minnie 1746 0.0179
6 1880 F Margaret 1578 0.0162
7 1880 F Ida 1472 0.0151
8 1880 F Alice 1414 0.0145
9 1880 F Bertha 1320 0.0135
10 1880 F Sarah 1288 0.0132
# ℹ 1,924,655 more rowsPopularity of “Amanda” over time
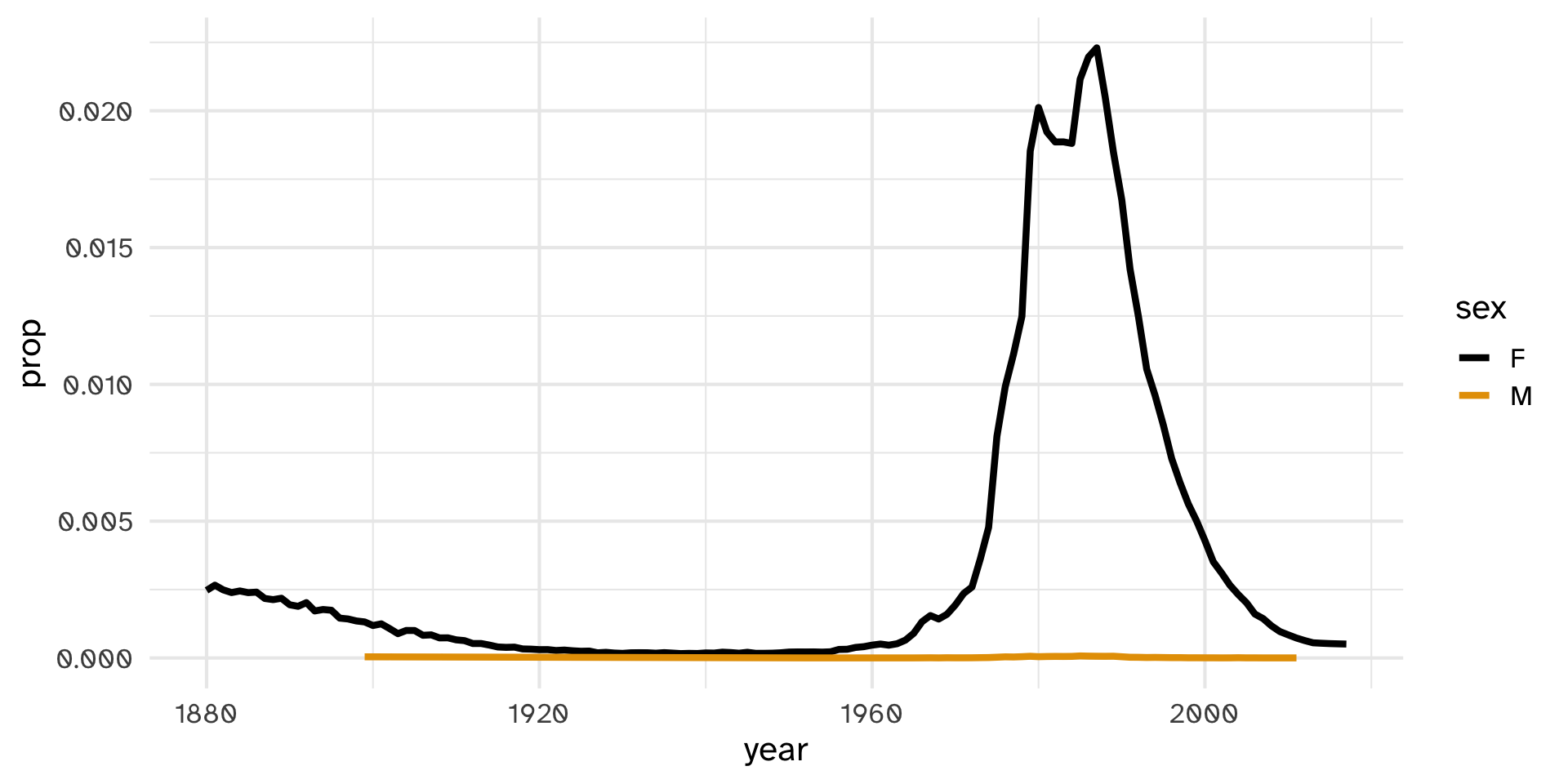
Replicate this plot with your own name. If your name doesn’t have enough data, try a friend or professor’s name
Babynames
# A tibble: 1,924,665 × 5
year sex name n prop
<dbl> <chr> <chr> <int> <dbl>
1 1880 F Mary 7065 0.0724
2 1880 F Anna 2604 0.0267
3 1880 F Emma 2003 0.0205
4 1880 F Elizabeth 1939 0.0199
5 1880 F Minnie 1746 0.0179
6 1880 F Margaret 1578 0.0162
7 1880 F Ida 1472 0.0151
8 1880 F Alice 1414 0.0145
9 1880 F Bertha 1320 0.0135
10 1880 F Sarah 1288 0.0132
# ℹ 1,924,655 more rowsExample questions:
- How many names end in a vowel?
- How many names contain the pattern “stat”
- How many names contain 3 A’s?
Extract substrings
-
string= character vector -
start/end= position of the first and last characters
Extract substrings
We can pull apart strings from the start…
Extract substrings
… or the end
Your turn:
What will the following commands return?
02:00
Your turn (again):
Confer with folks around you. Fill in the blanks of the .Rmd file to…
Isolate the last letter of every name
Create a logical variable that displays whether the last letter is one of “a”, “e”, “i”, “o”, “u”, or “y”.
Use a weighted mean to calculate the proportion of children whose name ends in a vowel by year (see
?weighted.mean)and then display the results as a line plot.
06:00
Extract substrings
What about a vector of strings?
[1] "ppl" "ine" "ear" "ran" "eac" "ana"Pad strings
We can add character(s) to the beginning or end of a string
Use the courses dataset in the .rmd file to answer the following:
How many of the course numbers end in
.00? Usestr_detect()orstr_count()to help you answer this question.The section number appears after the decimal point. Use
mutate()andstr_sub()to create asectioncolumn containing this number.How many courses contain the word
Introduction? Does case matter here?What is the longest course name (in terms of characters)? What is the shortest course name? Use
str_length()to help you answer this question.Which course name is comprised of the most words? To do this, create a new column containing the words in each title using
mutate()andstr_split(). Then, create another column calculating thelength()of the values in column you just created.Use
str_subset()to return the course names that contain exclamation points (!).
Regular Expressions
Regular expressions
-
Sometimes the patterns we wish to detect, extract, etc. too complex for exact matching
- Extract all time stamps of the form
HH:MM:SS - Extract the string that comes after the dash (e.g.
hw01-aluby)
- Extract all time stamps of the form
Regular expressions (regexps) are a very terse language that allow you to describe patterns in strings
Confusing at first, but extremely useful
Example
Suppose we wish to anonymize phone numbers in survey results
[1] "Home: 507-645-5489" "Cell: 219.917.9871"
[3] "My work phone is 507-202-2332" "I don't have a phone" Visualizing matches
The helper function str_view() finds regex matches
. match any character
Find a “-” and any (.) character that follows
[] match any occurence
Find any numbers between 0 and 9
[] match any occurence
Find any numbers between 2 and 7
Your turn:
Detect either “.” or “-” in the info vector.
02:00
Special patterns
There are a number of special patterns that match more than one character
-
\\d- digit -
\\s- white space -
\\w- word -
\\t- tab -
\\n- newline
Caution!
[^] match any occurence except
ANYTHING BUT numbers between 2 and 7
Anchors
Anchors look for matches at the start ^ or end $
[1] │ Home: 507-645-5489
[2] │ Cell: 219.917.9871
[3] │ My work phone is 507-202-2332
[4] │ I don't have a phoneUse regex in str_detect, str_sub, etc:
[1] │ Home: 507-645-5489
[2] │ Cell: 219.917.9871
[3] │ My work phone is 507-202-2332
[4] │ I don't have a phoneYour turn
Fill in the code to determine how many baby names in 2015 ended with a vowel.
Use a regular expression to specify the pattern.
03:00