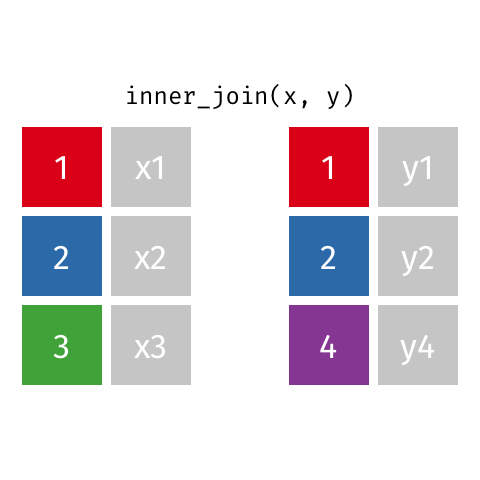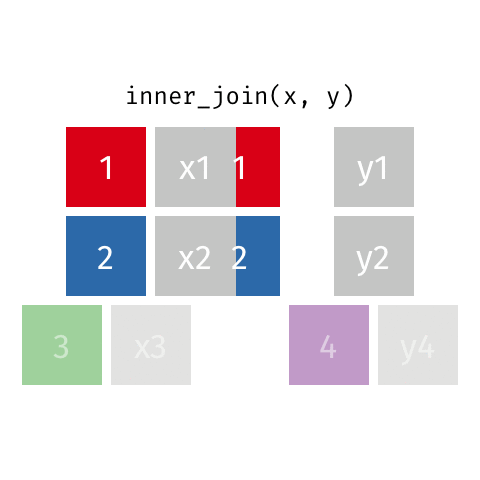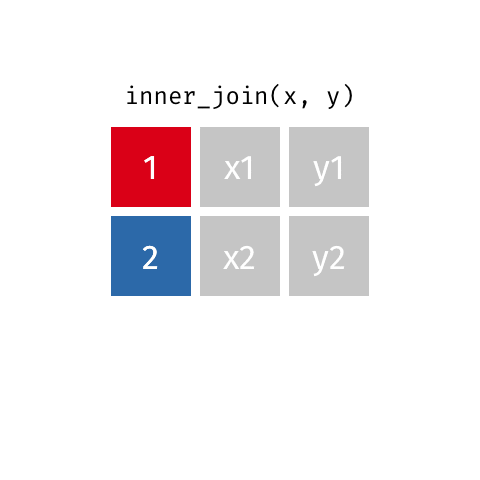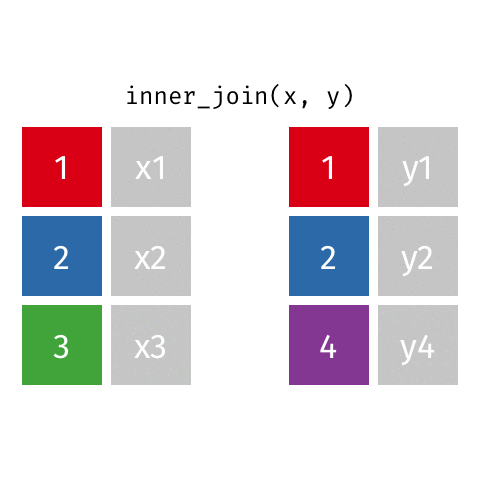
[1] "This course is awesome on so many levels. This is the best inferential statistics course I've come across. Here's why:*** The slides are beautiful and visually appealing, making following the rigorous content easier to digest.*** Instructors are captivating and articulate, the explanations are clear and concise.*** The assignments are very very tough, making the course incredibly challenging, but worth it. Honestly, I don't get why people give 1 star because the course is tough. This should be a huge plus.It was a real challenge getting 100% for everything. For every quiz, I attempted 2 - 3 times to get 100%. The challenge is worth it. I couldn't thank you enough for this course. You explain tough statistical concepts like the difference between prediction intervals and confidence intervals really well. Also, I think this course has the best teaching for Analysis of Variance (I have taken a few other statistics moocs). Also, your course helped me appreciate the meaning of R-squared, standard errors, confidence intervals in a very intuitive fashion. There are many other new things I've learnt from your course, some of them I thought I knew, but you helped me to either \"Aha\" or understand them more deeply.Before this course, most of the time statistics to me is like plug-and-play using procedures and and softwares. But now, I can understand the concepts and what the calculations really mean.Thank you for creating quizzes that make us really do step-by-step calculations and not just plug data into equations to get results like so many other statistics moocs do.The pedagogy is really great. Sometimes quizzes can be frustrating because I need to read very carefully into the meaning of the questions and all the options. However, the learning experience is really worth it.Again, thank you for an amazing course! This is rare stuff!It is without a doubt, a lot of passion and effort has been put into this course and this series."