Standardizing/rescaling/normalizing variables is often an essential first step in predictive modeling
Example:
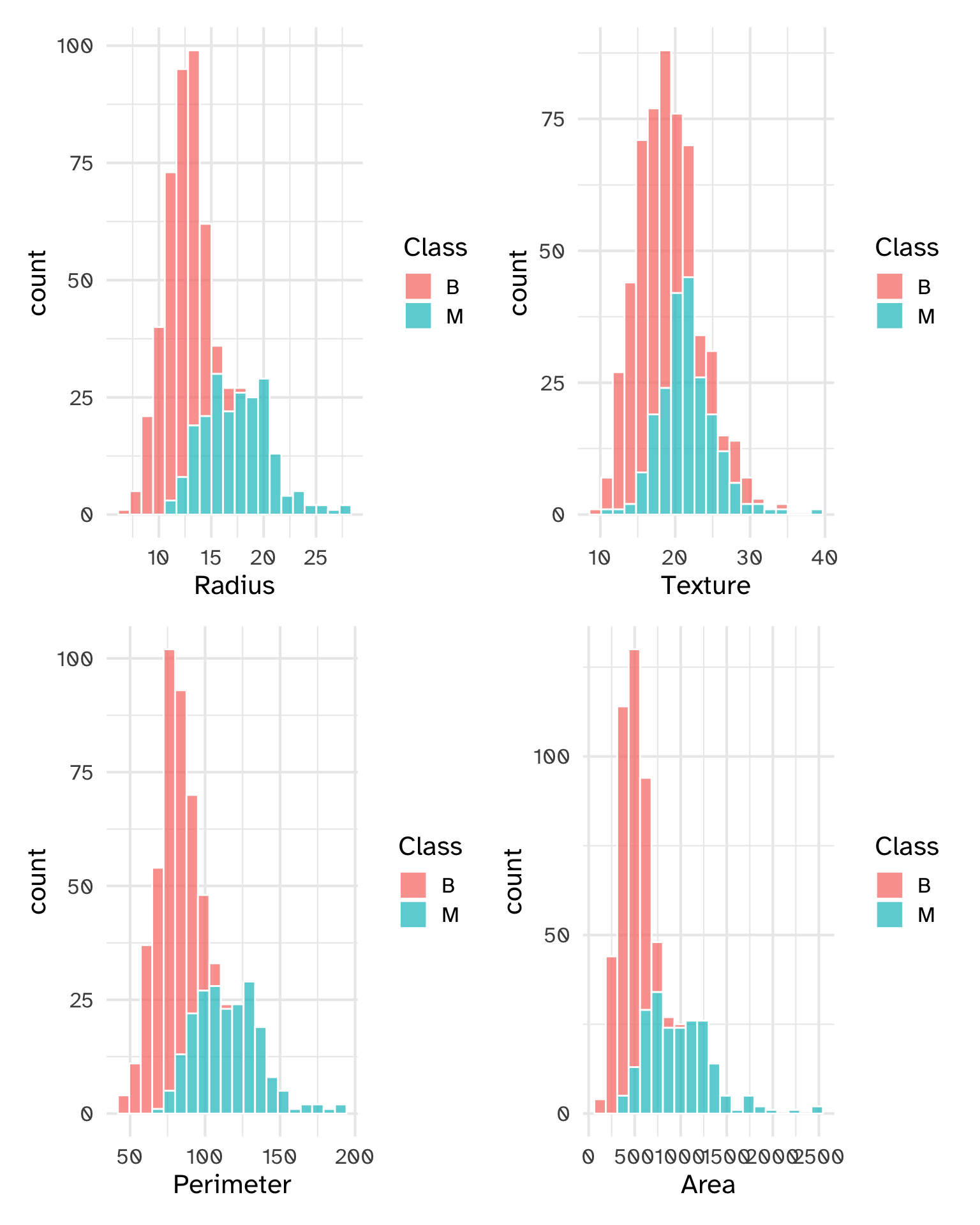
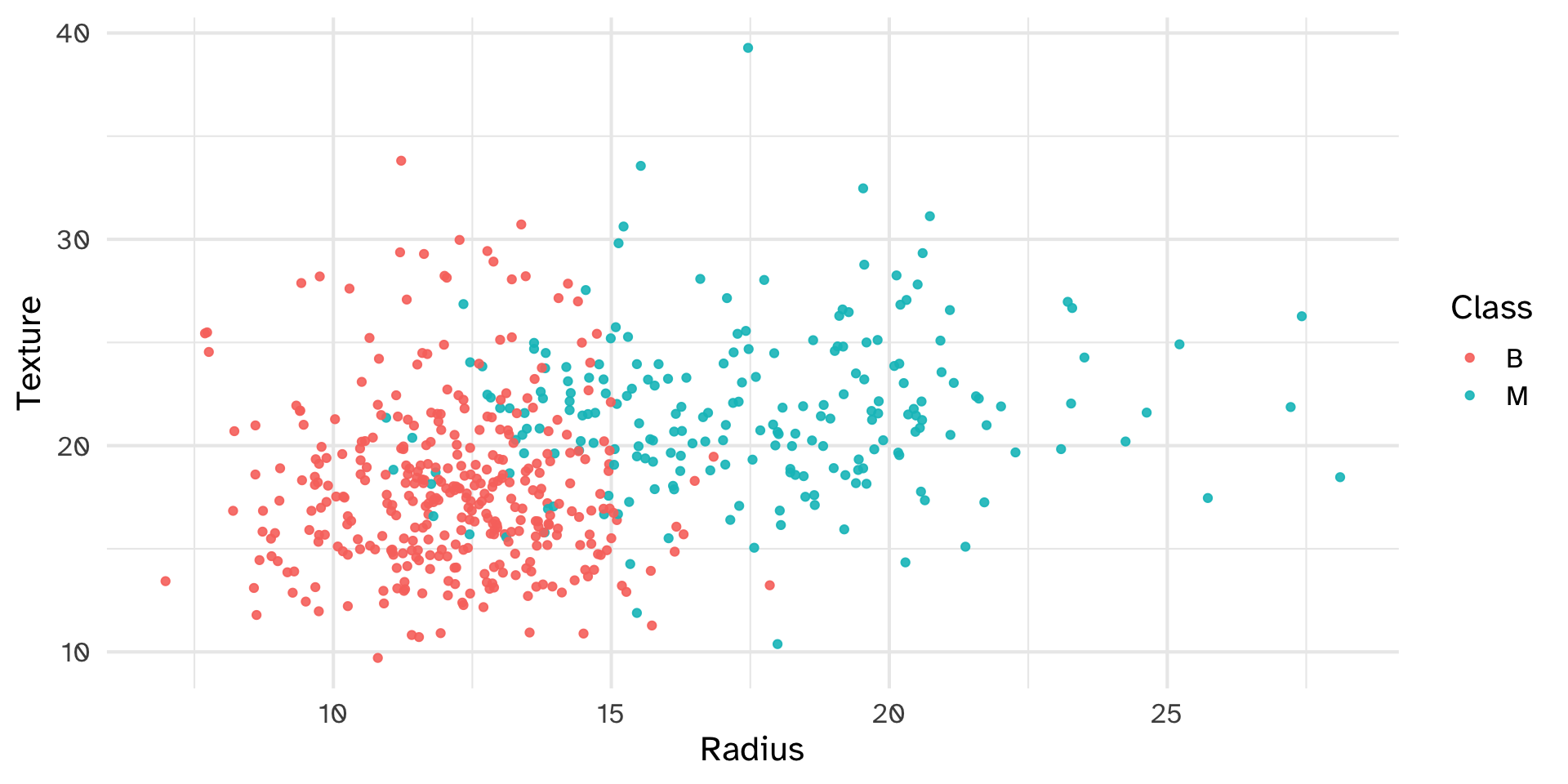
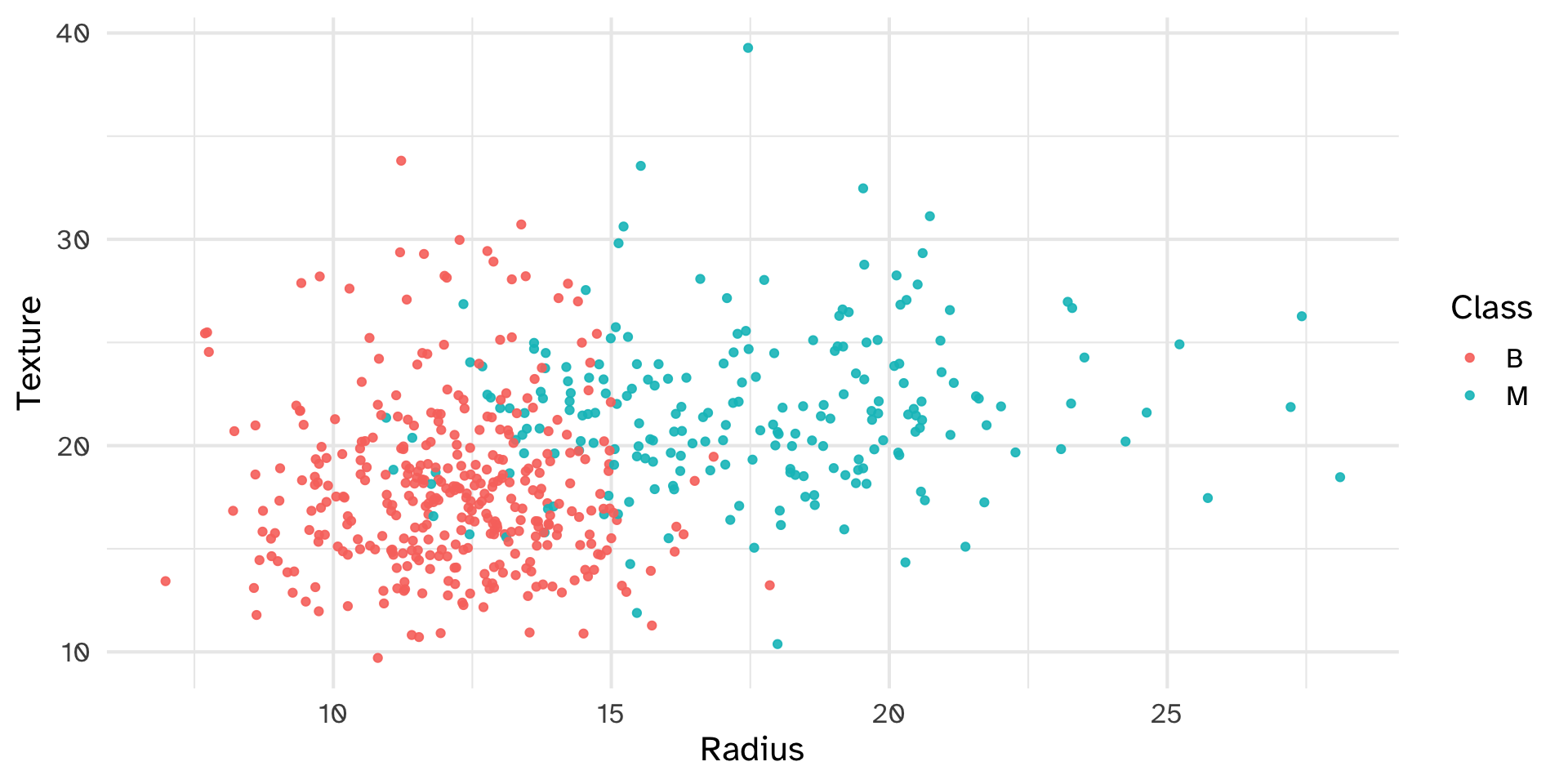
Set of digitized breast cancer image features
Each row in the data set represents an image of a tumor sample, including the diagnosis (benign or malignant) and several other measurements (nucleus texture, perimeter, area, etc.)
Diagnosis for each image was conducted by physicians.
# A tibble: 569 × 12
ID Class Radius Texture Perimeter Area Smoothness Compactness Concavity
<dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 8.42e5 M 18.0 10.4 123. 1001 0.118 0.278 0.300
2 8.43e5 M 20.6 17.8 133. 1326 0.0847 0.0786 0.0869
3 8.43e7 M 19.7 21.2 130 1203 0.110 0.160 0.197
4 8.43e7 M 11.4 20.4 77.6 386. 0.142 0.284 0.241
5 8.44e7 M 20.3 14.3 135. 1297 0.100 0.133 0.198
6 8.44e5 M 12.4 15.7 82.6 477. 0.128 0.17 0.158
7 8.44e5 M 18.2 20.0 120. 1040 0.0946 0.109 0.113
8 8.45e7 M 13.7 20.8 90.2 578. 0.119 0.164 0.0937
9 8.45e5 M 13 21.8 87.5 520. 0.127 0.193 0.186
10 8.45e7 M 12.5 24.0 84.0 476. 0.119 0.240 0.227
11 8.46e5 M 16.0 23.2 103. 798. 0.0821 0.0667 0.0330
12 8.46e7 M 15.8 17.9 104. 781 0.0971 0.129 0.0995
13 8.46e5 M 19.2 24.8 132. 1123 0.0974 0.246 0.206
14 8.46e5 M 15.8 24.0 104. 783. 0.0840 0.100 0.0994
15 8.47e7 M 13.7 22.6 93.6 578. 0.113 0.229 0.213
16 8.48e7 M 14.5 27.5 96.7 659. 0.114 0.160 0.164
# ℹ 553 more rows
# ℹ 3 more variables: Concave_Points <dbl>, Symmetry <dbl>,
# Fractal_Dimension <dbl>
Standardizing variables
Goal: standardize the 10 quantitative variables in the data set
Approach: subtract sample mean, divide by sample standard deviation
Turn the following code snippets into functions. Think about what each function does before you begin, and be sure to give each function an informative name.
mean(is.na(x))
x / sum(x, na.rm = TRUE)
sd(x, na.rm = TRUE) / mean(x, na.rm = TRUE)
You can test your functions on variables from the palmerpenguins::penguins dataset (e.g. my_func(penguins$flipper_length_mm)).
06:00
Return values
The value returned by the function is usually the last statement it evaluates
Write a function called column_mean that takes a data set and column name (as a string) as inputs and returns the column mean as output. (Hint: access the column using [[)
You should also include a na.rm argument and set the default to TRUE so that NAs are removed from the calculation by default.
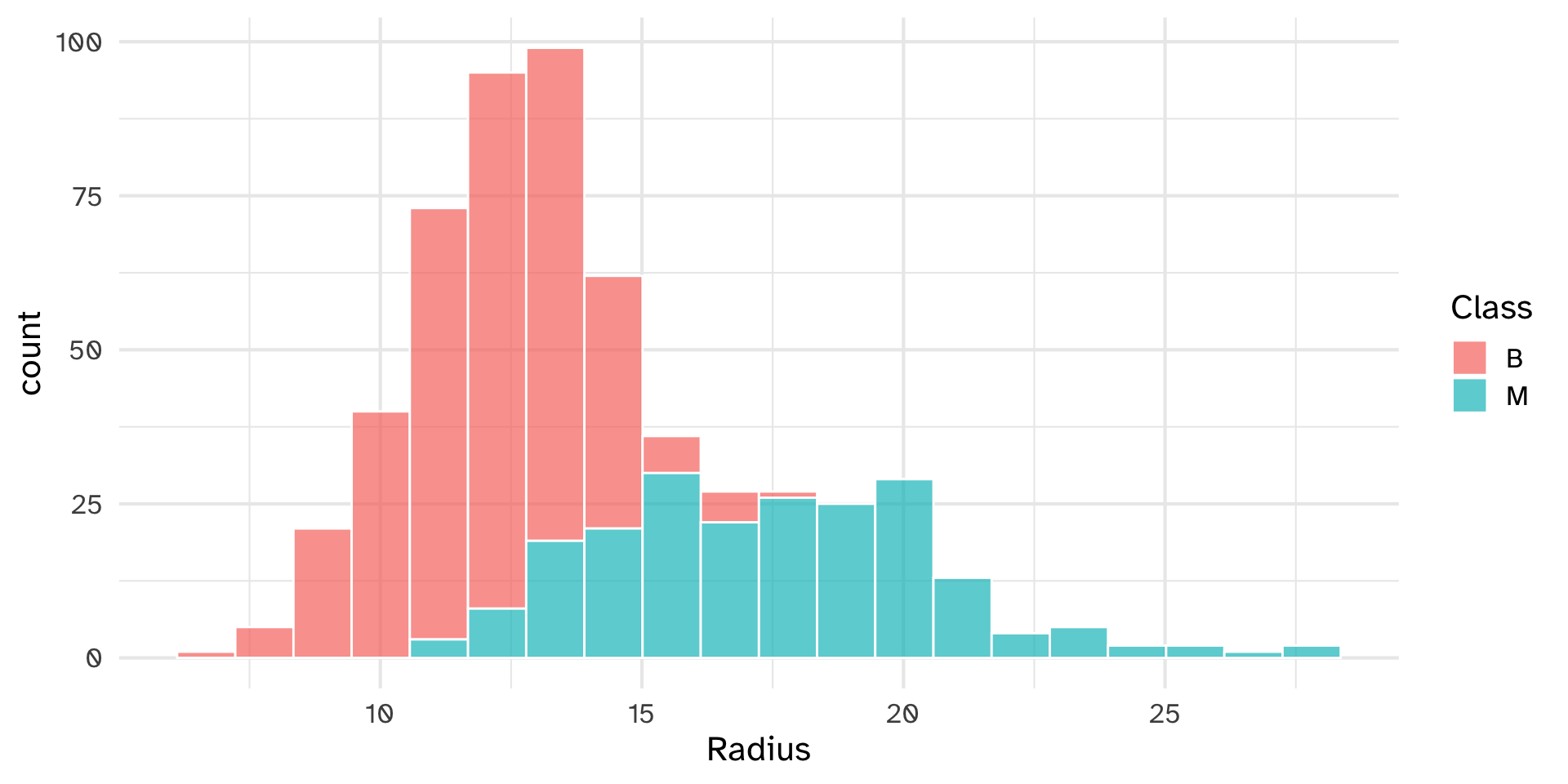
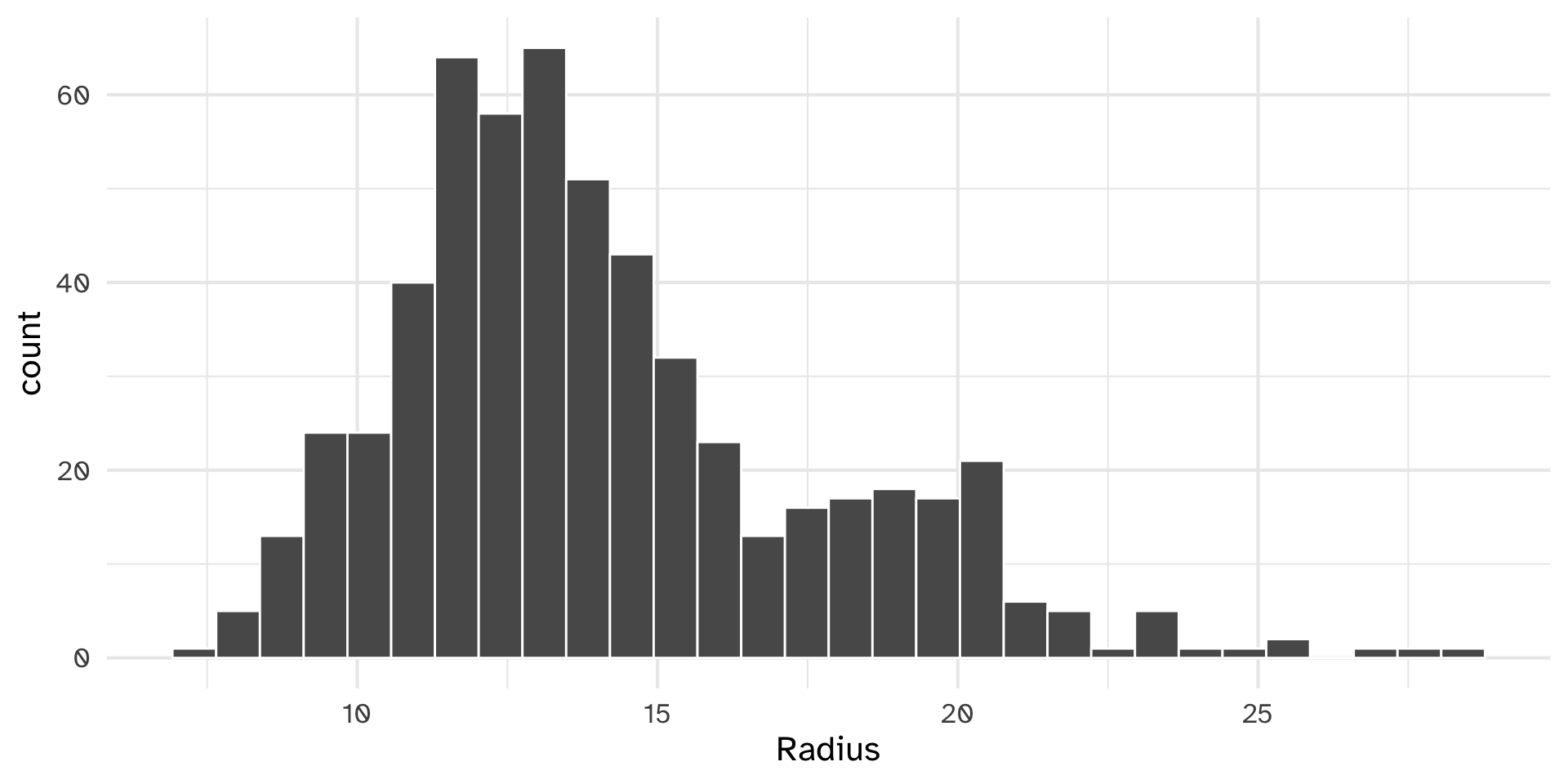
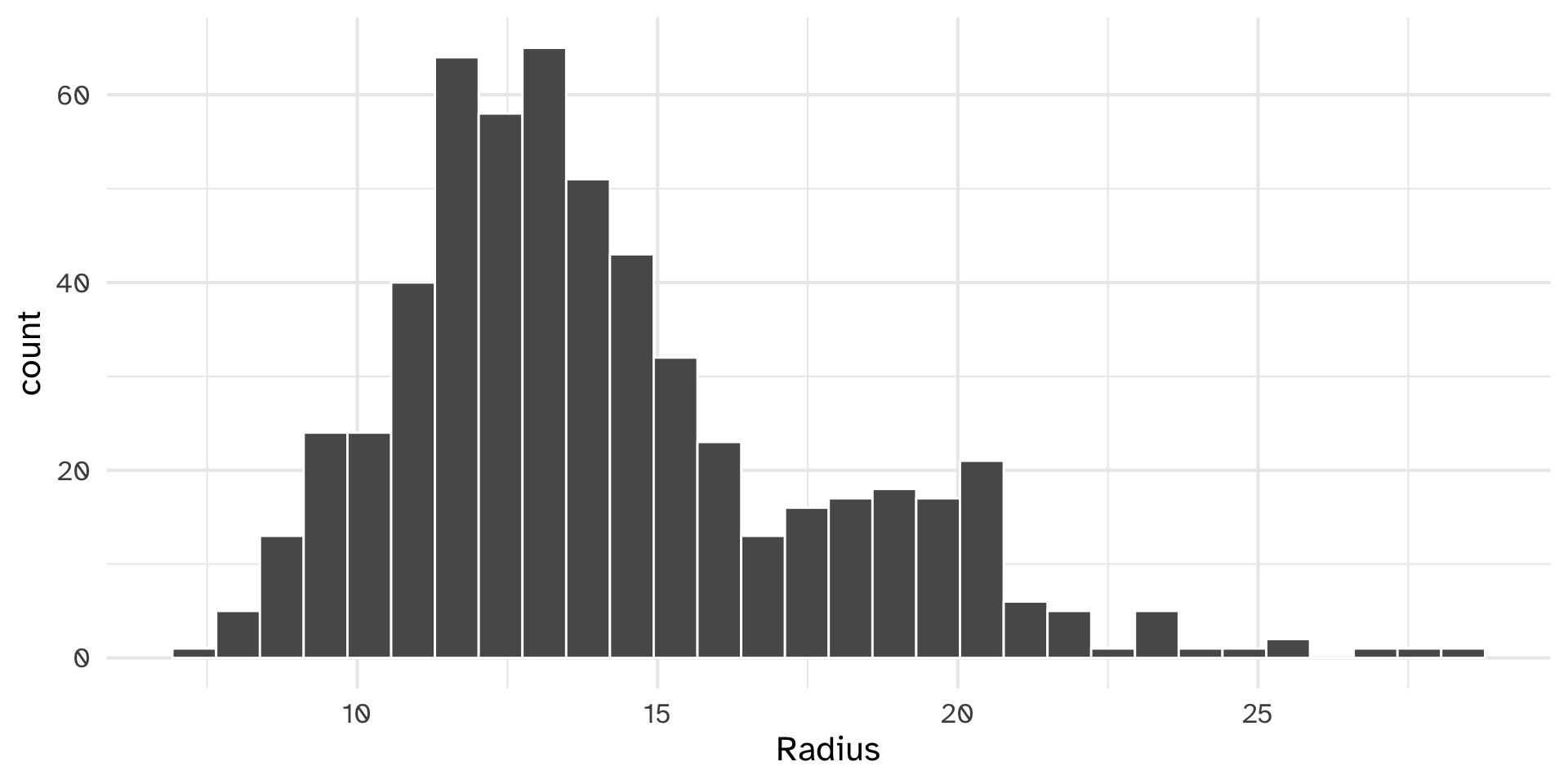
histogram <-function(df, var, bins =20) { df %>%ggplot(aes(x = var, fill = Class)) +geom_histogram(col ="white", bins =20, alpha = .7) }histogram(unscaled_cancer, Radius)
Error in `geom_histogram()`:
! Problem while computing aesthetics.
ℹ Error occurred in the 1st layer.
Caused by error:
! object 'Radius' not found
🤗 embracing 🤗
This issue arises in {dplyr} and {ggplot} functions because they use a special kind of evaluation, which allows us to refer to our variable names directly.
To write our own functions that use these packages, we use 🤗 embracing 🤗 (wrap the variable in braces). This tells R to use the value stored inside the argument, not the argument as the literal variable name.
One way to remember what’s happening is to think of { } as looking down a tunnel — { var } will make a dplyr function look inside of var rather than looking for a variable called var.
Edit your scatterplot function to include an argument called draw_line. If draw_line is TRUE, your function should add a line of best fit to your scatterplot. Test your function with the following examples